Zacznijmy od tego, czym właściwie jest ORM i dlaczego jest tak często wykorzystywany przez programistów. ORM jest to mapowanie obiektowo-relacyjne, czyli sposób odwzorowywania bazy danych na obiektach wykorzystywanych w językach programowania i na odwrót. Dzięki takiemu rozwiązaniu, możemy w szybki sposób używać w swoich aplikacjach obiektów przechowywanych w wewnętrznych bazach danych bez pisania odpowiednich metod komunikacji i prasowania danych.
Tworzenie aplikacji na system android z wbudowaną bazą danych SQLite bez używania ORM, polegał na stworzeniu klasy, która będzie odpowiadała za obsługę bazy danych oraz klas obsługujących każdą tabelę. Wszystko polegało na tworzeniu zapytań SQL, mniej lub bardziej skomplikowanych, ale na pewno czasochłonnych. Każda akcja, którą chcieliśmy w późniejszym czasie użyć, musiała zostać ręcznie napisana. Należało do nich:
- tworzenie, aktualizacja i usuwanie tabel,
- dodawanie, usuwanie, aktualizacja rekordu dla każdej tabeli,
- pozostałe metody działające na tabelach np. pobieranie wszystkich rekordów, wyszukiwanie rekordu po identyfikatorze itp.
Zajmowało to wiele czasu, a ponadto była to praca odtwórcza – polegała głównie na dostosowaniu do danego projektu, wcześniej stworzonej klasy z innego projektu.
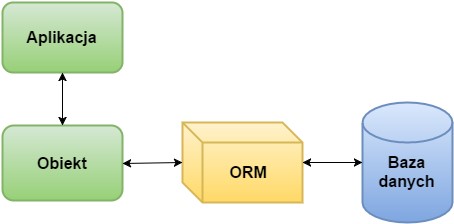
Sugar ORM odpowiada za interakcję między bazą danych a aplikacją. Biblioteka ta zastępuje ręcznie tworzone klasy komunikacji z bazą danych i znacznie przyśpiesza stworzenie jej w projekcie.
Cały proces instalacji oraz zastosowania Sugar ORM został opisany na stronie projektu http://satyan.github.io/sugar/index.html. Ten artykuł nie będzie powielaniem treści znajdującej się na stronie, lecz dopowiedzeniem niektórych kwestii i wyjaśnieniem problemów, na które można trafić podczas używania tej biblioteki.
Rozpoczynając konfigurację biblioteki SugarORM w projekcie, ważnym elementem jest, aby deklarowany w pliku AndroidManifest.xml numer wersji bazy danych na początku ustalić na 2. Odpowiada on za stworzenie bazy danych i jej aktualizację, przez co ustalając tą wartość początkową na 1, możemy trafić na problemy z utworzeniem bazy danych przy pierwszym uruchomieniu aplikacji.
Wartość ta służy również do aktualizacji struktury bazy i tabel. Gdy w trakcie tworzenia lub rozwijania projektu, zwiększymy tą wartość, aplikacja podczas uruchamiania będzie wiedziała, że baza danych uległa zmianie i w folderze assets będzie szukać odpowiedniego pliku sql aktualizacji bazy. Plik ten powinien mieć taką samą nazwę, jak numer wersji nowej bazy danych np. „3.sql”. W takim pliku możemy napisać polecenia do bazy danych, które zmodyfikują ją do najnowszej wersji np. dodać, usunąć bądź zmodyfikować pola tabeli lub dodać do niej kolejne kolumny.
Podczas konfiguracji, możemy natrafić na jeszcze jeden problem. Gdy chcemy użyć własnej klasy aplikacji, a jednocześnie konfiguracja wymaga użycia klasy SugarApp. W takim przypadku możemy skorzystać z dziedziczenia, a w pliku manifestu użyć swojej klasy.
Tworzenie tabel w bazie danych z wykorzystaniem biblioteki Sugar ORM jest znacznie prostsze niż rozwiązanie standardowe. Polega wyłącznie na dziedziczeniu w klasie obiektu po klasie SugarRecord. Automatycznie zostanie stworzona tabela zawierająca wszystkie pola znajdujące się w danej klasie z wyjątkiem tych, oznaczonych tagiem @Ignore.
Możemy komunikować się z bazą danych za pomocą prostych i szybkich w użyciu metod opisanych na stronie projektu. Dzięki nim możemy zapisać/zmienić stworzony w programie obiekt, wczytać lub skasować już istniejący o konkretnym Id lub wczytać listę wszystkich obiektów. W bardzo prosty sposób możemy również napisać własne parametry wyszukiwania obiektów w bazie. Korzystając z tych metod cały czas pracujemy na obiektach, co w programowaniu obiektowym jest bardzo wygodne. Zadaniem biblioteki Sugar ORM jest konwersja obiektów z naszego programu i zapisanie ich w bazie danych a następnie umożliwienie pracy na nich, prawie bez styczności z językiem SQL.
Sugar ORM ma jednak swoje minusy. Moim zdaniem największym, jest jego szybkość przy dużej ilości danych. Wykorzystując wbudowane metody możemy jedynie wyciągać z bazy danych obiekty składające się ze wszystkich istniejących pól. Przy dużej ilości danych, w pewnych momentach potrzebujemy tylko części parametrów i w takim wypadku musimy napisać własne zapytanie sql do bazy danych omijając bibliotekę Sugar ORM.
Najbardziej czasochłonne jest jednak rzutowanie obiektów z bazy danych, wyciągniętych za pomocą biblioteki, na obiekty istniejące w naszym programie. Zautomatyzowane rozpoznanie typu każdego pola, a następnie przypisanie go do właściwej zmiennej obiektu, sprawia, że jest to bardzo czasochłonne. Przykładowo wczytując 13 tysięcy obiektów składających się z 40 zmiennych, trwa to około 40 sekund (w zależności od urządzenia). Taki czas ładowania aplikacji mobilnej jest nie do zaakceptowania dla przeciętnego użytkownika. W takim wypadku, optymalnym rozwiązaniem będzie użycie własnego zapytania sql do pobrania obiektów bazy danych, a następnie napisanie parsera obiektu Cursor, dzięki któremu w szybki sposób nadamy odpowiedni typ zmiennym i przypiszemy do właściwych pól naszego obiektu.
Automatyczna konwersja obustronna baza danych <-> obiekty, jest oczywiście bardzo wygodnym rozwiązaniem dla programistów, które znacznie przyśpiesza pracę z bazą danych. Mimo swoich wad z czasem wczytywania dużej ilości obiektów oraz niekiedy problemów z konfiguracją początkową, biblioteka Sugar ORM stała się nieodłącznym elementem każdego mojego projektu.