Asystenci głosowi – nowy trend
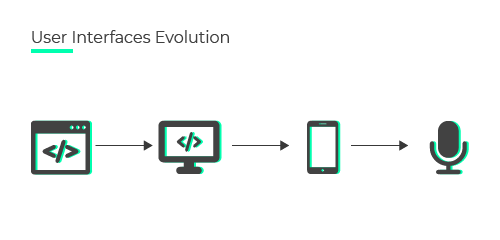
GUI, czyli Graficzny Interfejs Użytkownika, umożliwia komunikację między ludźmi i komputerami. Pierwszy GUI, jak zwykło się określać, to wiersz poleceń (inaczej: terminal). Użytkownik wpisuje polecenie, jakąś frazę, którą komputer może zrozumieć. Takie rozpoznawanie mowy można z pewnością nazwać nowym trendem w aplikacjach mobilnych.
Wielu programistów nadal używa go do wykonywania niektórych zadań. Wprowadzenie okienkowego interfejsu użytkownika – pulpitu, doprowadziło komputery pod niemal każdy dach.
Następnie rewolucja w telefonach komórkowych przyniosła interfejs wielodotykowy (nasz pierwszy smartfon od Apple), w którym palec był głównym punktem interakcji z urządzeniami. Bardziej intuicyjne rozwiązanie, ale wciąż trzeba było uczyć użytkowników, jak korzystać z poszczególnych aplikacji.
I w końcu, chociaż nie nowa, ale rewolucyjna koncepcja zrezygnowania z GUI na rzecz komend głosowych. Wraz z rozwojem technologii sieci neuronowych, nauczania maszynowego, sztucznej inteligencji, zaczynamy wchodzić w erę interakcji głosowych z urządzeniami.
Co prawda, jeszcze trochę czasu minie zanim na dobre ta idea ruszy. Wszystko ze względu na trudność, jaką jest odpowiednie zrozumienie mowy przez sztuczną inteligencję. Niejeden z nas ma czasem problem ze zrozumieniem drugiego człowieka, ale trzeba być gotowym na to, że sztuczna inteligencja poradzi sobie już dziś z tym problemem znacznie lepiej od nas.
Technologie
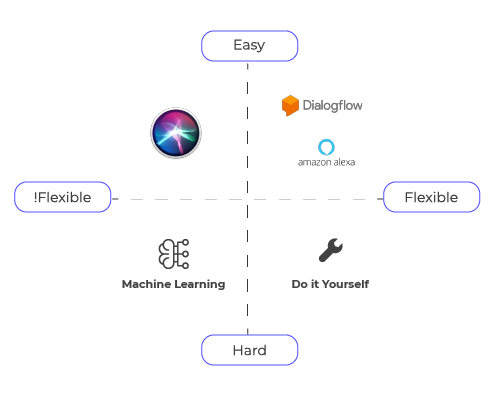
Na rynku dostępnych jest kilka technologii, które umożliwiają integrację interfejsu asystenta głosowego z aplikacją. Tu podzielimy je na 4 sekcje – w zależności od elastyczności i trudności w implementacji. Spróbujmy to sobie zobrazować – technologie Apple mają dość niską elastyczność i możliwości dostosowywania. SiriKit jest najłatwiejszy do zintegrowania, a Core ML jest nieco trudniejszy, ponieważ wymaga specjalistycznych umiejętności uczenia maszynowego. Idealną grupą jest łatwa i elastyczna sekcja, w której mamy kilka platform NLU (rozumienia naturalnego języka), takich jak: Dialogflow, Wit.ai, Amazon Lex. W sekcji najtrudniejszej zawsze możemy zrobić wszystko sami. Jest to skomplikowane i kosztowne (będziemy potrzebować dużo infrastruktury, pamięci masowej, zaawansowanych algorytmów), ale daje nam elastyczność – możemy zrobić to na swój sposób. Niestety dla rozwiązań w naszym ojczystym języku, część oferowanych rozwiązań, jak np. Siri, która nie zna jeszcze polskiego, nie będzie tak łatwa do użycia jak dla developerów anglojęzycznych. (Ja w dalszej części skupię się na wybranym przez nas rozwiązaniu, czyli skorzystaniu z Dialogflow oferowanego przez Google.)
Dialogflow
Dialogflow o platforma rozpoznawania naturalnego języka (NLU) należąca do Google. Zapewnia aplikację internetową, w której można tworzyć własnych agentów i szkolić ich w zakresie, jaki jest nam potrzebny w tworzonej aplikacji. Możemy także skorzystać z już przeszkolonych agentów. Dla każdego agenta definiujemy „Intent”.
Intent to w uproszczeniu cel całej sentencji/ zdania, jakie wprowadził użytkownik – to co chce otrzymać w odpowiedzi. Intenty składają się z czterech głównych komponentów, które umożliwiają mapowanie tego, co użytkownik mówi do tego, co odpowiada twój agent. Komponenty te obejmują:
- nazwę Intentu: identyfikuje dopasowaną intencję,
- frazy szkoleniowe: przykłady tego, co użytkownicy mogą powiedzieć, aby dopasować konkretny zamiar,
- akcje i parametry: określają, w jaki sposób istotne informacje (parametry, encje) są wyodrębniane z wypowiedzi użytkownika,
- odpowiedź: treść wyświetlana użytkownikowi.
Przykład: „Czy będę potrzebował dzisiaj cieplejszej kurtki?” Encje – czyli takie pogrupowane słowa klucze, które pozwalają nam lepiej zrozumieć, co użytkownik miał na myśli; w powyższym zdaniu takim słowem będzie np. „dzisiaj” – określa nam czas, jaki interesuje użytkownika.
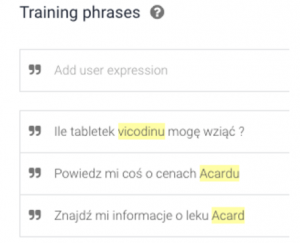
Na powyższym screenie tworzymy Intent – Znajdź_Informacje_Leki z nazwami leków jako encjami tego intentu. Szkolimy agenta, podając jak najwięcej zdań i zaznaczając encje-nazwy leków- żółte są wtedy, gdy szukamy nazwy leku. Oznaczają też, że są dodane do konkretnego zbioru encji. Z czasem agent uczy się obsługiwać nawet nieznane wcześniej zdania.
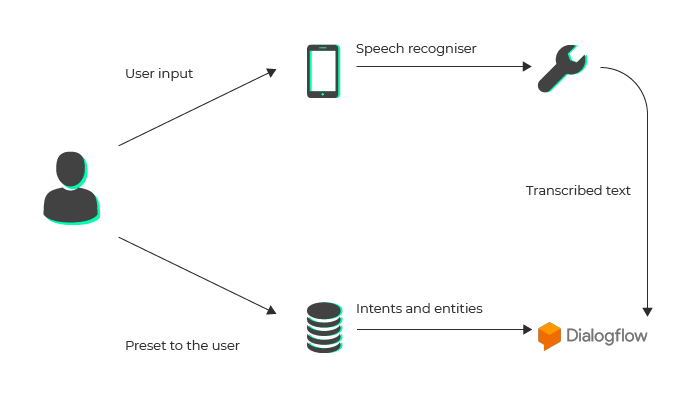
Poniżej ogólny schemat wyjaśniający, jak działa idea rozpoznawania mowy przy użyciu Dialogflow. Po przekazaniu wyrażenia mówionego przez użytkownika jest ono tłumaczone na zwykły tekst przy użyciu struktury mowy Apple. Następnie treść jest wysyłana do Dialogflow, który przetwarza tekst i wyodrębnia intencję i powiązane z nią elementy, zwracając odpowiedź JSON-em. Zapisujemy te informacje i prezentujemy je użytkownikowi w naszym widoku Asystenta. Bardzo podobnie działają inne rozwiązania korzystające z platformy NLU, jak np. Wit.ai.
W iOS korzystamy z biblioteki Speech, która daje nam możliwość rozpoznawania mowy także w języku polskim, niestety nie jest ona tak dobra, jak oferowane na Androidzie narzędzia od Googla – miejmy nadzieję, że z czasem i algorytmy NLU z Cupertino dogonią swoich młodszych konkurentów. Po syntezie mowy na tekst, musimy przesłać treść do naszego Agenta na serwerach Google. Do 23 września 2019 roku dostępne będzie iOS SDK, niestety, po tym terminie zostanie wyłączone i doda nam to trochę pracy, bo komunikację REST-ową będziemy musieli napisać sami. Jako że jest to dość nowa gałąź technologii, nie ma jeszcze w Internecie zbyt wielu informacji, jak zintegrować Dialogflow 2.0 dla iOS-a, a i dokumentacja nic na ten temat nie wspomina. Niech to was nie odstrasza – nie zawsze musi być wszystko podane na tacy, jak więcej się nakombinujemy, to lepiej zapamiętamy jak ze zdobytej wiedzy korzystać. ;) Kolejno, po otrzymaniu zwrotki z Dialogflow i jej odkodowaniu z jsona do tekstu, możemy: wyświetlić użytkownikowi odpowiedź albo nie tylko wyświetlić, ale i przy użyciu biblioteki AVFoundation odczytać ją użytkownikowi. W skrócie – te dwie biblioteki musicie zaznajomić sobie, aby rozpocząć przygodę z rozpoznawaniem naturalnej mowy w języku polskim na systemie iOS.
Praktyka czyni mistrza
Po teorii – czas na kod! Po zaimportowaniu biblioteki Speech, nasz View Controller powinien korzystać z metod SFSpeechRecognizerDelegate, czyli na prostym przykładzie: Ustawiamy język, w jakim będziemy gadać i przygotowujemy sobie potrzebne rzeczy.
@IBOutlet weak var microphoneButton: UIButton!
private let speechRecognizer = SFSpeechRecognizer(locale: Locale.init(identifier: "pl-PL"))!
private var recognitionRequest: SFSpeechAudioBufferRecognitionRequest?
private var recognitionTask: SFSpeechRecognitionTask?
private let audioEngine = AVAudioEngine()Następnie musimy przygotować autoryzację. Możecie to zrobić, a nawet powinniście w oddzielnej metodzie. Ja na potrzeby tego szybkiego wyjaśnienia zrobiłem to w ViewDidLoad, bo jestem leniwy.
override func viewDidLoad() {
super.viewDidLoad()
microphoneButton.isEnabled = false
speechRecognizer.delegate = self
SFSpeechRecognizer.requestAuthorization { (authStatus) in
var isButtonEnabled = false
switch authStatus {
case .authorized:
isButtonEnabled = true
case .denied:
isButtonEnabled = false
print("User denied access to speech recognition")
case .restricted:
isButtonEnabled = false
print("Speech recognition restricted on this device")
case .notDetermined:
isButtonEnabled = false
print("Speech recognition not yet authorized")
}
OperationQueue.main.addOperation() {
self.microphoneButton.isEnabled = isButtonEnabled
}
}
}
Taki szablonowy przykład funkcji odpowiedzialnej za nagrywanie głosu – to tutaj odbywa się cała magia naszego zapisu mowy w tekst, no może nie do końca cała magia, bo rozpoznawanie mowy dzieje się na serwerach Apple. W naszym kodzie jest to funkcja:
func startRecording() {
if recognitionTask != nil {
recognitionTask?.cancel()
recognitionTask = nil
}
let audioSession = AVAudioSession.sharedInstance()
do {
try audioSession.setCategory(AVAudioSession.Category.playAndRecord, mode: .measurement, options: .defaultToSpeaker)
try audioSession.setMode(AVAudioSession.Mode.measurement)
try audioSession.setActive(true, options: .notifyOthersOnDeactivation)
} catch {
print("audioSession properties weren't set because of an error.")
}
recognitionRequest = SFSpeechAudioBufferRecognitionRequest()
let inputNode = audioEngine.inputNode
guard let recognitionRequest = recognitionRequest else {
fatalError("Unable to create an SFSpeechAudioBufferRecognitionRequest object")
}
recognitionRequest.shouldReportPartialResults = true
recognitionTask = speechRecognizer.recognitionTask(with: recognitionRequest, resultHandler: { (result, error) in //7
var isFinal = false
if result != nil {
let bestString = result?.bestTranscription.formattedString
self.detectedTextLabel.text = bestString
var lastString: String = ""
for segment in (result?.bestTranscription.segments)! {
let indexTo = bestString?.index((bestString?.startIndex)!, offsetBy: segment.substringRange.location)
lastString = bestString!.substring(from: indexTo!)
}
self.checkForColorsSaid(resultString: lastString)
isFinal = (result?.isFinal)!
}
if error != nil || isFinal {
self.audioEngine.stop()
inputNode.removeTap(onBus: 0)
self.recognitionRequest = nil
self.recognitionTask = nil
self.microphoneButton.isEnabled = true
}
})
let recordingFormat = inputNode.outputFormat(forBus: 0)
inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) { (buffer, when) in
self.recognitionRequest?.append(buffer)
}
audioEngine.prepare()
do {
try audioEngine.start()
} catch {
print("audioEngine couldn't start because of an error.")
}
textView.text = "Powiedz coś, słucham Cię!"
}Jak skorzystać z syntezatora mowy? – dajmy głos naszemu rozwiązaniu:
@IBAction func playNote(_ sender: Any) {
let string = self.tkscior?.text
let utterance = AVSpeechUtterance(string: string ?? "Brak tekstu")
utterance.voice = AVSpeechSynthesisVoice(language: "pl-PL")
let synth = AVSpeechSynthesizer()
synth.speak(utterance)
}Mamy przykład jak rozpoznać głos, i jak go odczytać, to kawałek kodu do komunikacji z api.ai
import UIKit
import Alamofire
class AIRequest {
var query: String
var lang: String
var sessionId: String
init(query: String, lang: String) {
self.query = query
self.lang = lang
self.sessionId = "WB-" + Date().ticks.description
}
func getHeaders() -> HTTPHeaders {
let clientAccessToken = "Wasz token dostepny w panelu agenta api.ai"
let headers: HTTPHeaders = [
"Authorization": "Hubert " + clientAccessToken,
]
return headers
}
func toParameters() -> Parameters {
let parameters: Parameters = [
"query": query,
"lang": lang,
"sessionId": sessionId
]
return parameters
}
}
//6 import UIKit
class URLGenerator {
static let AIbaseUrl: String = "https://api.api.ai"
static let AIversion: String = "v1"
class func apiUrlForPath(path: String) -> NSURL {
let urlString = URLGenerator.AIbaseUrl + "/" + URLGenerator.AIversion + "/" + path
return NSURL(string: urlString)!
}
class func aiApiUrlForPathString(path: String) -> String {
return URLGenerator.AIbaseUrl + "/" + URLGenerator.AIversion + "/" + path
}
}Oczywiście nie jest to całe rozwiązanie tego kodu. Jest tego cała masa. To jedynie pogląd, jak to wszystko może wyglądać. Trochę informacji do przyswojenia, mózg paruje, ale czas zacząć tworzyć własne rozwiązania dla asystentów głosowych w naszych aplikacjach. Wykorzystajmy narzędzia jakie daje nam Apple i Google, aby stało się to możliwe.
Voicebot zyska na popularności
Gałąź technologii, jaką jest rozumienie języka naturalnego i analiza mowy jest naprawdę ekscytująca. Rzeczy zmieniają się dość szybko i możemy spodziewać się wielu ulepszeń i innowacji w tej dziedzinie. Wykorzystanie głosowych asystentów będzie rosnąć z czasem. Dzięki wprowadzeniu języka polskiego do platform typu Dialogflow oraz dodaniu polskiego języka do syntezatorów mowy Apple, możemy z całą pewnością spodziewać się wzrostu liczby aplikacji z głosowymi asystentami skierowanymi do polskojęzycznych odbiorców nie tylko na Androidzie, ale także na iOS.
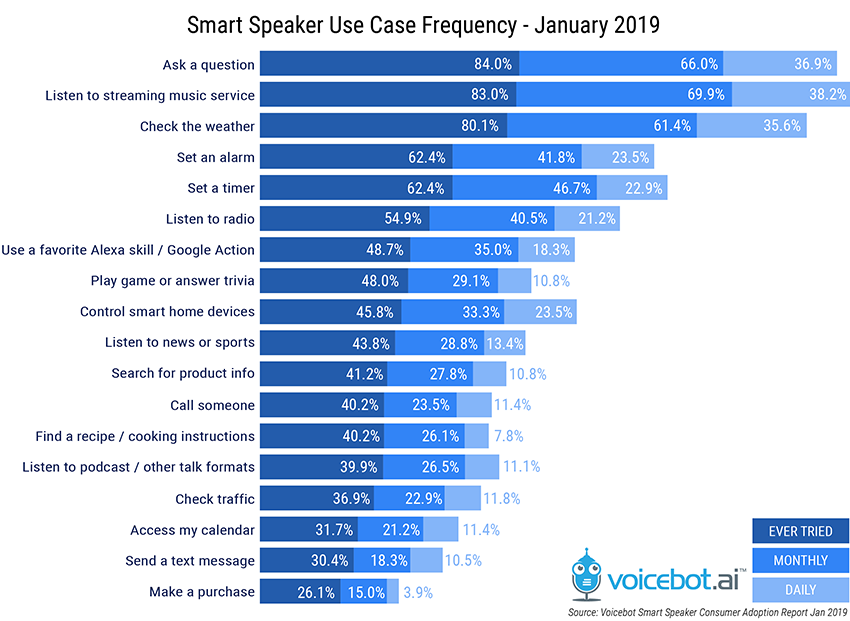
Na koniec jeszcze infografika, do jakich zadań, i jak często obecnie używamy asystentów głosowych:
Więcej o wykorzystaniu technologii w systemie iOS możesz przeczytać w artykułach o: